Tülu 3: Democratizing Advanced AI Model Development

The Allen Institute for AI (AI2) has released Tülu 3, a groundbreaking open-source post-training framework aimed at democratizing advanced AI model development. This comprehensive suite includes state-of-the-art models, training datasets, code, and evaluation tools, enabling researchers and developers to create high-performance AI models rivaling those of leading closed-source systems. Tülu 3 introduces innovative techniques such as Reinforcement Learning with Verifiable Rewards (RLVR) and extensive guidance on data curation and recipe design. By closing the performance gap between open and closed fine-tuning recipes, Tülu 3 empowers the AI community to explore new post-training approaches and customize models for specific use cases without compromising core capabilities.
Introduction to Tülu 3
Tülu 3 is a new open-source post-training framework developed by the Allen Institute for AI (AI2) ¹ that aims to democratize advanced AI model development. It represents a significant step forward in closing the performance gap between open and closed fine-tuning recipes, outperforming other open-weight post-trained models of the same size, including Llama 3.1-Instruct.
Currently, Tülu 3 offers 8B and 70B parameter versions, with a 405B version planned for the future. These models are based on Meta’s Llama 3.1 framework and have been fine-tuned on an extensive dataset mix comprising publicly available, synthetic, and human-created data.
The significance of Tülu 3 lies in its ability to empower researchers, developers, and enterprises to post-train models to the quality of leading closed models, reducing dependence on private companies or middlemen. This advancement in open-source AI capabilities and transparency has the potential to foster innovation and enable transformative solutions across various domains.
The Importance of Post-Training
Post-training has emerged as a critical step in the development of usable AI models. While pre-training creates the foundation, post-training is essential for adding safety measures and instruction-following abilities. As noted in the blog post, “The base pre-trained LMs are neither safe nor robust for public use and interactions, thus require post-training” ¹.
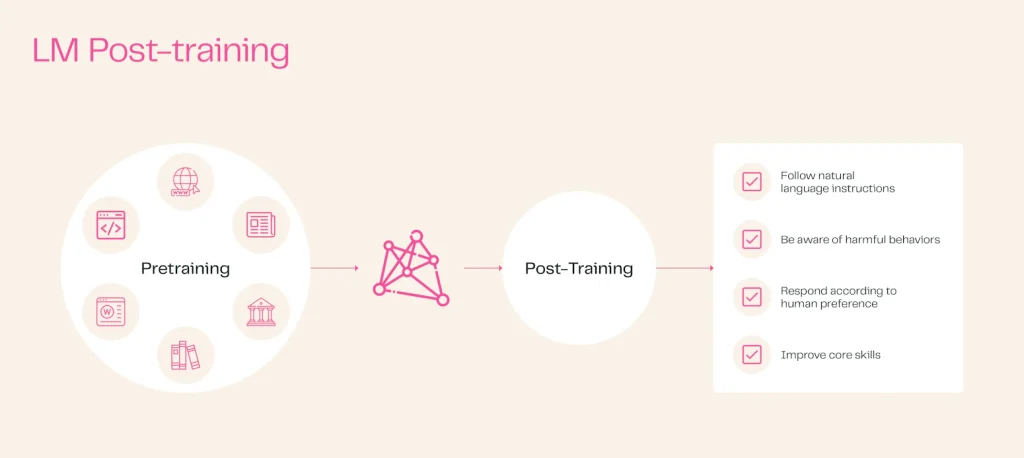
The evolution of post-training techniques has been rapid, moving from limited human datapoints to complex multi-stage processes. Early approaches like InstructGPT have given way to more sophisticated techniques used by major AI companies. However, the current state of open-source post-training has seen a saturation of recipes and knowledge, with hints of more complex post-training methods being developed in closed labs.
Tülu 3 addresses this gap by introducing new methods and datasets to push the boundaries of open post-training research. As stated by the Allen Institute for AI, “Tülu 3 pushes the boundaries of research in post-training and closes the performance gap between open and closed fine-tuning recipes” ¹.
Key Components and Features of Tülu 3
Tülu 3 comprises several key components that contribute to its effectiveness:
- Tülu 3 Data: Carefully curated training datasets, including public and synthetically generated prompts targeting core skills.
- Tülu 3 Code: Improved training infrastructure and pipeline for data selection through evaluation.
- Tülu 3 Eval: Reproducible evaluation toolkit for guiding development and assessment.
- Tülu 3 Recipe: Innovative methodologies and training guidance, including a five-part post-training recipe.
A notable feature is the introduction of Reinforcement Learning with Verifiable Rewards (RLVR), a novel approach for training on tasks with verifiable outcomes. As described in the technical report, “RLVR leverages the existing RLHF objective but replaces the reward model with a verification function” ².
The framework provides comprehensive coverage of the post-training process, allowing for customization of model capabilities. It also focuses on scaling preference data with on-policy generations and offers extensive guidance on evaluation and recipe design.
Training Process and Techniques
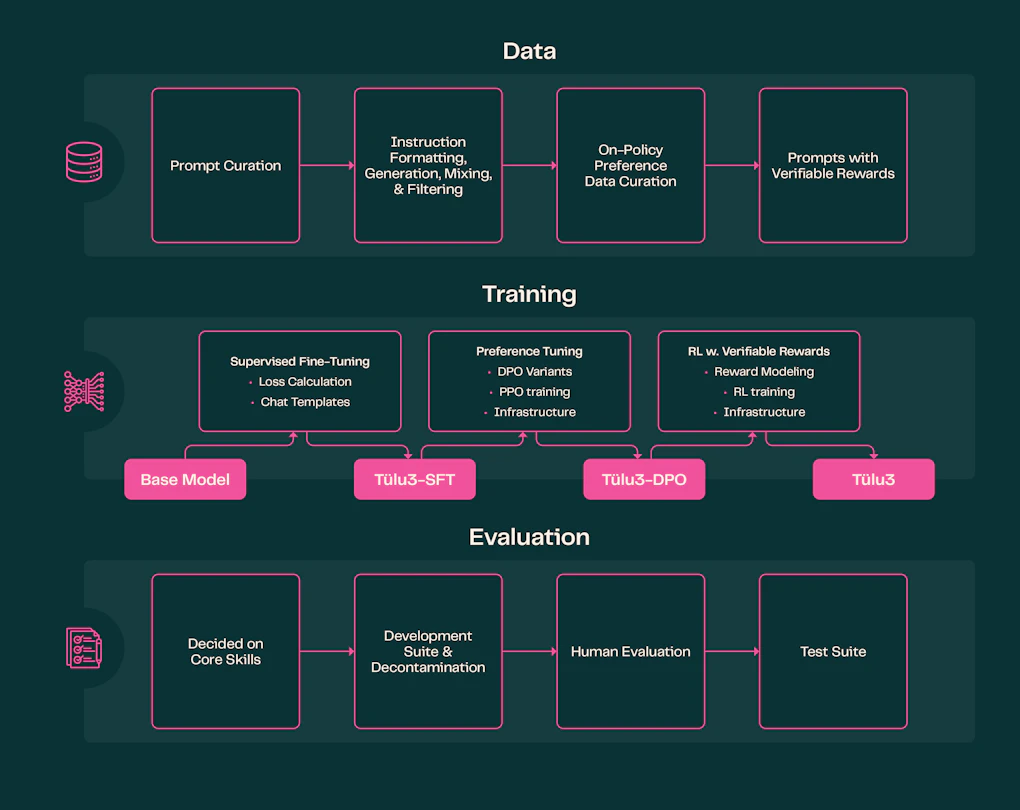
Tülu 3 employs a five-part post-training recipe that includes:
- Prompt curation
- Supervised finetuning (SFT)
- Direct Preference Optimization (DPO)
- RLVR
- Standardized evaluation
The data curation process involves a mix of public datasets and synthetically generated prompts, focusing on diverse and high-quality prompts targeting core skills. The Allen Institute for AI notes: “To target the desired core skills, we curate a diverse and high quality set of prompts from publicly available datasets with clear provenance and synthetically generate prompts to fill any gaps” ².
Preference tuning is achieved through the conversion of prompts into preference data using both on-policy and off-policy models. The process experiments with various preference algorithms, with DPO emerging as the preferred method due to its simplicity and efficiency.
Performance and Applications
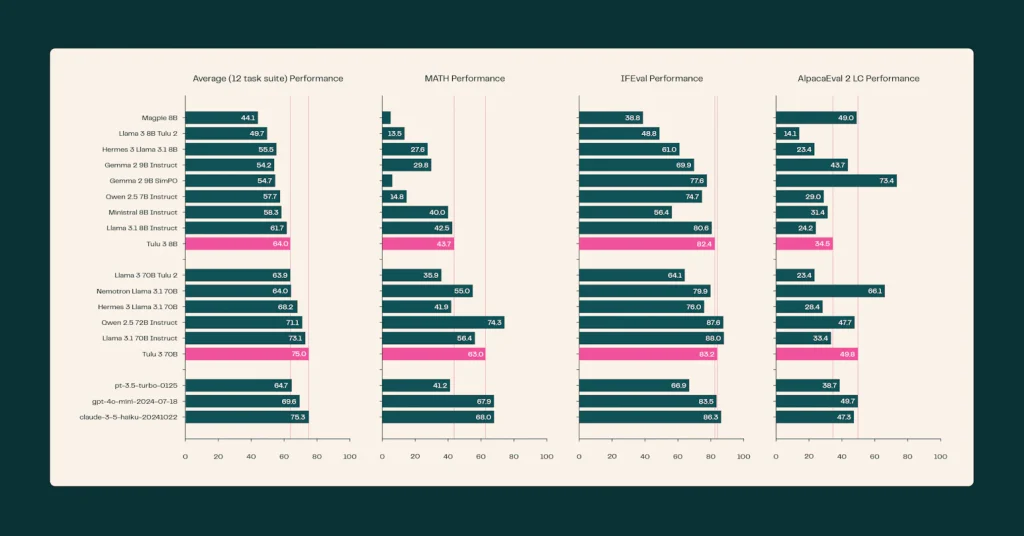
Tülu 3 has demonstrated impressive performance, outperforming other open-weight models of the same size and closing the gap to proprietary model capabilities. “Tülu 3 models have demonstrated remarkable performance across multiple benchmark evaluations” ³.
The models excel in conversational tasks, complex reasoning, coding, and creative applications. They have shown strong performance in safety tasks and various benchmarks like MATH, GSM8K, and IFEval.
Tülu 3’s versatility makes it suitable for a wide range of applications, including education, research, technical problem-solving, content generation, summarization, and coding. The models’ adaptability allows for customization to specific use cases while maintaining core capabilities.
Openness and Accessibility
A key aspect of Tülu 3 is its commitment to openness and accessibility. All data, recipes, code, infrastructure, and evaluation frameworks have been made public: “AI2 has made the models, training datasets, evaluation code, and methodologies fully open-source” ³.
The models, training datasets, evaluation code, and methodologies are fully open-source, allowing for transparent examination and reproduction of results. An interactive demo is available through AI2 Playground for hands-on exploration of the models’ capabilities ⁴.
Tülu 3 is licensed under Meta’s Llama 3.1 Community License Agreement, primarily for research and educational purposes. This openness fosters innovation and collaboration within the AI community.
Limitations and Responsible Use
Despite its impressive capabilities, Tülu 3 has some limitations that users should be aware of. The models have limited safety training, and AI2 acknowledges the potential for problematic outputs under certain conditions: “AI2 acknowledges that the models have limited safety training and are not equipped with in-the-loop filtering mechanisms like some proprietary models” ³.
The exact composition of the training dataset of the Llama 3.1 models by Meta remains undisclosed, raising potential concerns about biases. To address these challenges, AI2 has provided guidelines for responsible use and emphasized the importance of using the models primarily for research and educational purposes.
Future Developments and Implications
Looking ahead, AI2 is planning to release an OLMo-based, Tülu 3-trained model, which will offer a fully open-source solution from pre-training to post-training. OLMo (Open Language Model) is AI2’s fully open-source large language model, designed to provide complete transparency in its development process. This development has the potential to further advance open-source AI capabilities and foster innovation in the field.
The implications of Tülu 3 for enterprises are significant. It increases confidence in open-source model performance and offers more choices for integrating AI into business stacks. “Tülu 3 offers enterprises more of a choice when looking for open-source models to bring into their stack and fine-tune with their data” ⁵.
Tülu 3 represents a major step forward in democratizing advanced AI model development. By providing a comprehensive, open-source post-training framework, it empowers researchers, developers, and enterprises to create high-performance AI models that can compete with leading closed-source systems. As AI solutions continue to evolve, initiatives like Tülu 3 will play a crucial role in fostering innovation, transparency, and accessibility in AI development.
Sources:
- https://allenai.org/blog/tulu-3
- https://allenai.org/blog/tulu-3-technical
- https://www.marktechpost.com/2024/11/21/the-allen-institute-for-ai-ai2-releases-tulu-3-a-set-of-state-of-the-art-instruct-models-with-fully-open-data-eval-code-and-training-algorithms/
- https://playground.allenai.org/
- https://venturebeat.com/ai/ai2-closes-the-gap-between-closed-source-and-open-source-post-training/
[…] https://www.theaiobserver.com/tulu-3-democratizing-advanced-ai-model-development/ […]