Breaking Boundaries: NVIDIA’s Sana Brings 4K AI Images to Consumer Hardware

NVIDIA, in collaboration with MIT and Tsinghua University, has introduced Sana, a new text-to-image AI framework capable of generating high-quality images up to 4096×4096 resolution with remarkable efficiency. Sana combines innovative techniques including a deep compression autoencoder, linear diffusion transformer, and a decoder-only text encoder to achieve superior performance while significantly reducing model size and computational requirements. The framework outperforms larger models in both speed and quality metrics, generating 1024×1024 images in under a second on consumer-grade hardware. Sana shows promise in delivering high-resolution images with improved efficiency, but it still faces significant challenges in text-image alignment and consistency, indicating that further development is needed before it can be considered a game-changer in AI-driven image generation.
Introduction
Sana, a new text-to-image AI framework developed by NVIDIA, MIT, and Tsinghua University, represents a significant advancement in small model AI-driven image generation ¹ ² ³. This innovative system offers an improved approach to creating high-resolution images, combining efficiency, quality, and accessibility on consumer-grade hardware in a way that distinguishes it from existing models in the field.
Core Technology and Design Elements
At the heart of Sana’s capabilities lies a series of carefully engineered components that work in concert to achieve its remarkable performance. The framework employs a Deep Compression Autoencoder (DC-AE) that pushes the boundaries of image compression, achieving a 32x reduction in size compared to the traditional 8x compression seen in most autoencoders. This aggressive compression significantly reduces the number of latent tokens required for image generation, playing a crucial role in Sana’s ability to efficiently produce ultra-high-resolution images.
The model’s architecture also features a Linear Diffusion Transformer (DiT), which replaces conventional quadratic attention mechanisms with linear attention. This innovation reduces computational complexity from O(N²) to O(N), allowing for more efficient processing of high-resolution images without sacrificing quality. The incorporation of Mix-FFN with 3×3 depth-wise convolution further enhances the local information processing capabilities of the model.
Another key innovation in Sana’s design is the use of a decoder-only text encoder. By leveraging Gemma, a small but powerful language model, Sana achieves superior text comprehension and instruction-following abilities. This approach, coupled with the implementation of complex human instructions (CHI), enables improved image-text alignment through in-context learning.
Performance and Efficiency
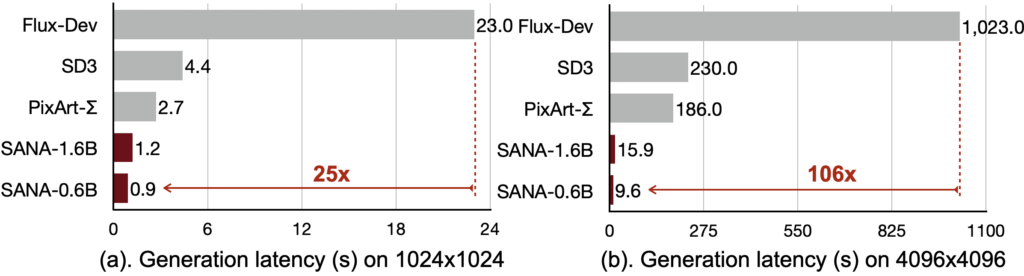
Sana’s performance metrics are nothing short of impressive. The 0.6B parameter version of the model demonstrates throughput that is five times faster than comparable models like PixArt-Σ for 512×512 resolution images, while significantly outperforming it across various quality metrics including FID, CLIP Score, GenEval, and DPG-Bench. At 1024×1024 resolution, Sana continues to excel, offering performance that rivals or surpasses models with substantially larger parameter counts.
Perhaps most remarkably, Sana-0.6B can be deployed on a laptop GPU with just 16GB of VRAM, generating 1024×1024 resolution images in less than one second. This level of efficiency opens up new possibilities for content creation at lower costs and with greater accessibility. When compared to state-of-the-art models like FLUX-dev, Sana-0.6B achieves comparable accuracy on benchmark tests while offering throughput that is 39 times faster.
Real-World Capabilities and Applications
In practical applications, Sana demonstrates a diverse range of capabilities.
The model claims to excel in generating clear text within images, making it suitable for tasks such as creating neon signs and banners. However, tests have shown that when generating texts with multiple words, Sana often produces unreliable results, with hallucinated letters or words appearing in place of the intended text. This limitation suggests that while Sana may perform well with short, simple text elements, it struggles with longer or more complex textual content in images.
Sana’s performance with text generation in images has shown inconsistencies, particularly with longer phrases or complex text elements. For instance, when given the prompt “A dimly lit backstreet in a cyberpunk setting with an orange-turquoise neon sign saying ‘AI Augments'”, the model consistently failed to accurately render the word “Augments”. Instead, it produced variations with misspellings or entirely different words, highlighting the challenges Sana faces in accurately interpreting and generating specific text within images. This limitation underscores the need for further refinement in Sana’s text comprehension and generation capabilities, especially for applications requiring precise textual elements in generated images.


Sana demonstrates potential in various creative applications, including logo design and image generation across different styles. While it shows promise in producing high-quality results, it’s important to note that its performance may vary depending on the specific task and complexity of the request. The model’s versatility suggests it could be a valuable tool for a range of creative needs, though users should be aware of its current limitations and potential inconsistencies.
The model’s stability and responsiveness, as demonstrated in the online demo hosted by MIT ⁴, underscore its potential for real-world deployment. Users report consistent performance, with high-resolution images being generated within approximately 20 seconds at 1472×960 pixel resolution.
Limitations and Future Developments
While Sana represents a significant advancement in fast AI image generation on consumer-grade hardware, it is not without limitations. The model occasionally struggles with facial detail generation and may encounter difficulties with text understanding in longer prompts. Some anatomical inaccuracies have also been noted in certain generated images. These challenges highlight areas for potential improvement in future iterations of the model.
Despite its impressive capabilities for its size, Sana still exhibits some limitations in accurately rendering complex prompts. For instance, when given the prompt “A man with his thumb up, and holding a sign that says ‘AI Tester'”, the model produced an image with notable inaccuracies. The generated figure had hands with five knuckled fingers but no thumbs, contradicting the prompt’s specification. Additionally, the sign in the image read “AI Teser” instead of “AI Tester”, demonstrating difficulties in precise text reproduction. Unusual artifacts were also observed around the figure’s eyes, further highlighting areas where the model’s image generation capabilities could be improved. These observations underscore the ongoing challenges in AI image generation, particularly when it comes to accurately interpreting and rendering specific anatomical details and text elements within complex scenes.

The developers of Sana have released training and inference code on their GitHub page ⁵, and plan to release a model zoo, as well as enhance compatibility with popular frameworks like Diffusers and ComfyUI. These developments promise to further expand the accessibility and utility of Sana for researchers and practitioners in the field.
Conclusion
Sana represents a step forward in AI-driven image generation, particularly for consumer-grade hardware with smaller models. Its ability to produce high-quality images efficiently on modest computing resources marks a notable shift towards more accessible and practical AI applications.
While Sana demonstrates promising advancements in AI-driven image generation, it’s important to acknowledge its current limitations. The model struggles with accurately rendering complex prompts, often producing anatomical inaccuracies and misinterpreting textual elements. Its performance in generating high-quality images is inconsistent, particularly when dealing with longer phrases or intricate scenes. As the technology continues to evolve, addressing these shortcomings will be crucial for Sana to realize its full potential in practical applications across various domains. While it offers a glimpse into more accessible AI capabilities, significant improvements are still needed before it can truly transform high-resolution image creation for widespread use.
Sources: