Breaking the Frontier Model Barrier: Nous Research’s Forge Reasoning API Challenges Industry Leaders

Nous Research has unveiled the Forge Reasoning API Beta, a groundbreaking advancement in LLM inference technology that can potentially elevate open-source AI models to compete with frontier models. The system’s architecture combines three innovative components: Monte Carlo Tree Search (MCTS), Chain of Code (CoC), and Mixture of Agents (MoA). Initial testing shows remarkable results, with the open-source Hermes 70B model achieving competitive performance against industry leaders and notably outperforming OpenAI’s o1-preview on specific benchmarks like AIME. While currently in beta with select users and limited to single-turn capabilities, the API’s ability to enhance multiple models’ reasoning capabilities, including industry leaders like GPT-4 and Claude, suggests significant potential for advancing the entire LLM ecosystem.
Technical Architecture and Innovation
The Forge Reasoning API ¹ introduces a sophisticated three-pillar architecture designed to enhance LLM inference capabilities. The first pillar, Monte Carlo Tree Search (MCTS), systematically explores decision trees to optimize reasoning paths, enabling more structured problem-solving approaches. The Chain of Code (CoC) architecture serves as the second pillar, bridging the gap between natural language reasoning and computational execution by integrating code interpretation directly into the reasoning process. The third pillar, Mixture of Agents (MoA), orchestrates collaboration between multiple specialized agents, each contributing unique perspectives to complex problem-solving tasks. This integrated approach represents a significant departure from traditional inference methods, potentially offering a new paradigm for LLM reasoning capabilities.
Performance Metrics and Breakthrough Results
The most striking aspect of Forge’s performance is its ability to enhance the open-source Hermes 70B model (based on the llama 3 model) to compete with, and in some cases surpass, industry-leading models. Of particular note is its performance on the AIME mathematics competition metrics, where it outperforms OpenAI’s o1-preview ². The system achieves:
- 80.00% on AIME mathematics competition metrics
- 67.50% on MMLU-Pro
- 81.30% on MATH
- 45.32% on GPQA Diamond
These results are especially significant considering that Hermes 70B is substantially smaller than many frontier models. However, it’s crucial to interpret these benchmarks within context. While the results are promising, they represent performance under specific testing conditions and may not fully translate to all real-world applications.
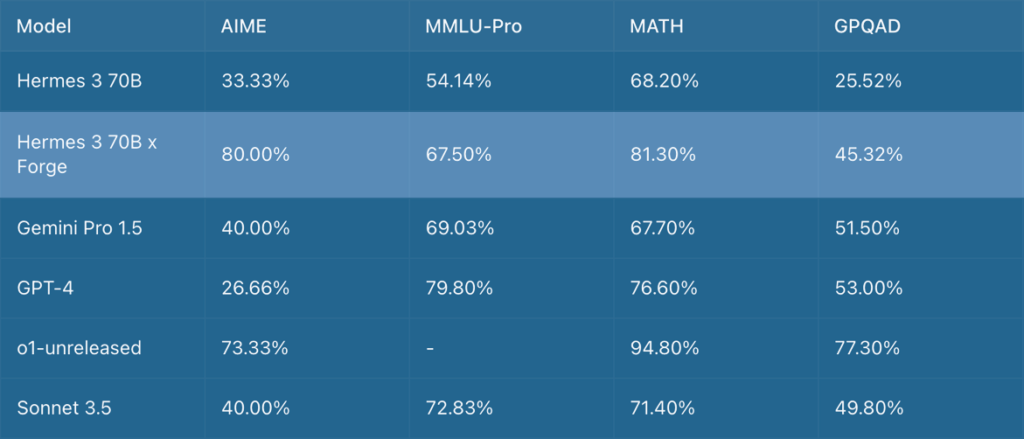
That being said, if these results are even approximately accurate, they could signify a revolutionary advancement in inference technology. The reported performance puts Forge on par with or potentially surpassing GPT-4 for certain benchmarks, and in the same league as OpenAI’s reasoning model o1 for the AIME benchmark.
Only time and extensive real-world application will determine if this reasoning layer can maintain its competitive edge. The true test of Forge’s capabilities will lie in its ability to consistently deliver high-quality results across diverse, practical scenarios beyond controlled benchmark environments.
Model Integration and Future Potential
Perhaps the most intriguing aspect of Forge is its model-agnostic design. While current benchmarks focus on Hermes 70B, the API supports integration with multiple leading models including GPT-4, Claude Sonnet 3.5, and Gemini. This raises a compelling possibility: if Forge can significantly enhance the reasoning capabilities of a 70B parameter model, its potential impact on larger, more sophisticated models like GPT-4 (estimated at over 1 trillion parameters) could be transformative. This scalability feature suggests that Forge might represent not just an improvement to existing models, but a fundamental advancement in how LLMs approach reasoning tasks.

Implementation and Technical Considerations
The Forge system achieves its performance while maintaining efficient resource utilization, demonstrating a 30% reduction in response latency compared to baseline implementations. This efficiency is particularly noteworthy given the complexity of the three-pillar architecture. The system’s ability to optimize inference paths suggests careful attention to computational overhead, making it viable for practical applications despite its sophisticated architecture.
Beta Program and Development Focus
The current beta phase specifically targets single-turn capabilities, allowing for focused testing and optimization of the core reasoning mechanisms. Through partnership with Lambda Labs, Nous Research is ensuring adequate computational resources for thorough testing. This controlled rollout approach allows for careful validation of the system’s capabilities before expanding to more complex multi-turn interactions.
Associated Developments
Alongside the Forge Reasoning API, Nous Research has launched Nous Chat ³, a streamlined interface featuring the Hermes 3 language model. This platform, available at https://hermes.nousresearch.com, offers a threaded conversation system and customizable prompts, demonstrating the practical application of the company’s advanced reasoning capabilities in a user-friendly format.
Conclusion
The Forge Reasoning API represents a potentially transformative development in LLM technology. Its ability to enhance open-source models to compete with proprietary frontier models suggests a possible democratization of advanced AI capabilities. While the initial results are impressive, particularly in outperforming OpenAI’s o1-preview on specific benchmarks, the true impact of this technology will be determined through extensive real-world application and independent verification. The potential application to larger models like GPT-4 and Claude opens up exciting possibilities for future advancements in AI reasoning capabilities.
Sources: