OpenAI’s Predicted Outputs: A Game-Changer for API Latency

OpenAI’s introduction of Predicted Outputs marks a significant advancement in API optimization, offering up to 5x faster response times for specific use cases. This feature, compatible with GPT-4o and GPT-4o-mini, allows developers to provide anticipated outputs, dramatically reducing processing time through speculative decoding. While primarily benefiting tasks with predictable outputs like document editing and code refactoring, the feature introduces new considerations for implementation, cost management, and optimization strategies. The innovation represents a crucial step toward making AI applications more suitable for real-time use cases.
Introduction
OpenAI’s recent announcement of Predicted Outputs ¹ represents a significant leap forward in addressing one of the most persistent challenges in AI application development: latency. The bigger the model, the slower the output will be, or maybe not. This new feature, designed specifically for GPT-4o and GPT-4o-mini models, introduces a novel approach to accelerating API response times by leveraging anticipated outputs. This development marks a crucial evolution in making AI applications more practical for real-time use cases.
Technical Foundation and Core Features
At the heart of this innovation lies speculative decoding, a sophisticated approach that fundamentally changes how the model processes information. Rather than generating content token by token, the system can now skip over predicted content, validating large batches of input simultaneously. This technical foundation enables the reported 5x improvement in response times for certain use cases. It’s like giving the AI a cheat sheet – if it knows what’s coming, it can zoom through the task much faster.
The feature’s effectiveness is particularly notable in scenarios where outputs are relatively predictable, such as document editing, code refactoring, or content updates. By allowing developers to provide anticipated outputs, the system can significantly reduce computational overhead, making it especially valuable for applications requiring rapid response times and turnarounds such as interactive code development. This feature proves particularly useful in scenarios like code refactoring, article editing, or document revisions, where the majority of the content is already written and only specific sections need modification.
Implementation and Practical Considerations
Successfully implementing Predicted Outputs requires careful consideration of several factors. The system’s effectiveness heavily depends on the accuracy of predictions, with divergences potentially leading to increased costs due to rejected prediction tokens. Developers must balance the potential speed benefits against the precision of their predictions. Think of it as a high-stakes game of “Guess What I’m Thinking” – the closer you guess, the faster and more efficient the process becomes.
The implementation process involves specific technical requirements, including proper environment configuration and API integration. Organizations looking to leverage this feature should focus on use cases where outputs are reasonably predictable, as this maximizes both performance benefits and cost efficiency. For example, companies offering code editors could implement this for quicker code completion, enhancing developer productivity. Similarly, writing aid tools could use it for faster autocomplete suggestions, improving user experience by reducing latency. For end users, this translates to more responsive applications and a smoother, more seamless interaction with AI-powered tools across various domains.
Cost and Performance Optimization
While the primary benefit of Predicted Outputs is improved latency, the feature introduces new considerations for cost management. The system charges for rejected prediction tokens at completion token rates, making prediction accuracy crucial for maintaining cost efficiency. Essentially it comes down to this: You get faster response times, but your costs stay the same or even go up slightly depending on your use case. It’s like ordering express shipping – you get your package faster, but you might end up paying a bit more for the convenience.
Performance monitoring becomes essential, with the system providing detailed metrics on prompt tokens, completion tokens, and both accepted and rejected prediction tokens. Real-world testing has demonstrated significant performance improvements, with documented cases showing processing time reductions from 5.2 to 3.3 seconds. However, these improvements must be weighed against potential cost increases when predictions diverge from actual outputs.
Best Practices and Implementation Strategies
Successful implementation of Predicted Outputs relies heavily on following established best practices. Organizations should focus on careful use case selection, prioritizing applications where outputs are predictable and consistent. Token management strategies, including concise prompting and structured output optimization, can further enhance performance benefits. It’s like fine-tuning a race car – every small adjustment can lead to better overall performance. Many applications could seamlessly transition between generating content from scratch and a faster editing mode for minor changes, operating behind the scenes without requiring manual user intervention.
Parallelization of non-sequential steps and consideration of alternative solutions for certain tasks can optimize overall system performance. The implementation of proper user experience elements, such as streaming responses and progress indicators, ensures that end users fully benefit from the improved response times. Essentially, the end user must see that progress is happening, even when there is still some waiting time involved.
Early Testing Results: A Case Study
The company FactoryAI had the opportunity to test Predicted Outputs, providing valuable insights into its real-world performance ². Over several days, they worked with OpenAI to evaluate the new feature in the chat completions API, focusing particularly on code editing tasks. Their findings offer a compelling glimpse into the potential of this technology:
- Response times were 2-4 times faster than existing models while maintaining high accuracy.
- Large file edits that previously took around 70 seconds were completed in approximately 20 seconds.
- Consistent sub-30 second response times were observed across various tests.
- Performance was equal to or better than other state-of-the-art models.
- Testing covered files ranging from 100 to over 3000 lines.
- Multiple programming languages were tested, including Python, JavaScript, Go, and C++.
FactoryAI’s experience suggests that breakthroughs in leveraging AI for software engineering tasks are not solely dependent on model size. Techniques like Speculative Decoding, which underpins Predicted Outputs, can unlock faster feedback loops and potentially enable entirely new feature sets that were previously impossible due to latency constraints.
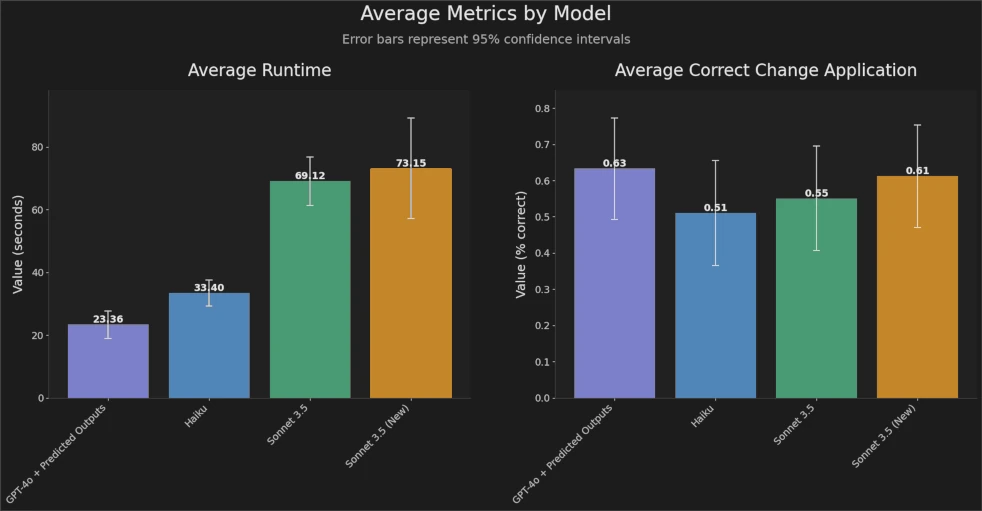
Screenshot from FactoryAI’s tweet ²: Average run times with predicted outputs drop from 73s (Claude Sonnet 3.5) to 23s (GPT-4o + predicted outputs). On the right: Average correct changes seem to be even slightly better than with Claude Sonnet 3.5.
It’s important to note that these results come from a single tester and cannot be generalized to all use cases or environments. However, the outcomes are promising and indicate the potential for significant improvements in AI-assisted coding and document editing tasks.
As more organizations and developers begin to implement and test Predicted Outputs, we can expect a broader range of data and experiences to emerge. This will provide a more comprehensive understanding of the feature’s capabilities, limitations, and optimal use cases across different industries and applications.
Future Implications and Industry Impact
The introduction of Predicted Outputs represents more than just a technical improvement; it signals a significant shift in how AI applications can be optimized for real-time use cases. This innovation opens new possibilities for applications requiring rapid response times, potentially expanding the practical applications of AI in time-sensitive scenarios. It’s like upgrading from a bicycle to a sports car – suddenly, you can cover much more ground in less time. You get GPT4o quality responses but at nearly the speed of the much smaller and faster GPT-4o mini.
We’re likely to see the emergence of new best practices and optimization strategies once more organizations begin implementing this feature. The technology’s impact on various industries could be substantial, particularly in sectors requiring near real-time AI processing capabilities such as code editing tools.
Conclusion
OpenAI’s Predicted Outputs feature represents a significant advancement in API optimization, offering substantial performance improvements for specific use cases. While the technology introduces new considerations for implementation and cost management, its potential benefits for real-time applications make it a valuable addition to the AI development toolkit.
Success with this feature requires careful attention to implementation details, ongoing optimization efforts, and a clear understanding of its strengths and limitations. As organizations continue to explore and implement this technology, we’re likely to see increasingly sophisticated applications that leverage its capabilities for improved performance and user experience: faster performance at the highest quality.
For developers and organizations looking to use this feature, the key is to choose the right tasks, test thoroughly, and keep a close eye on how well it’s working and what it costs. When used correctly, Predicted Outputs can make AI applications much better and faster, especially when you need quick responses and can guess what the output might be. It’s like having a fast-forward button for your AI – when you know what’s coming next, you can skip ahead and save time.
Sources: